
Why Sentence-by-Sentence Translation Won’t Deliver Hyper-Personalization
Writing, Translating and Hyper-personalization
Imagine this: you sit down to write something new. Do you immediately create a table and write each sentence into its own little cell? Of course not. Whether you’re crafting an email campaign, drafting an article, or putting together a report, you’ll open your editor and start writing, editing as you go, moving parts around, letting your ideas flow.
So here’s my question: if we can agree that writing sentence-by-sentence in table cells sounds absurd, why is that the expectation in our industry for how translation will be carried out?
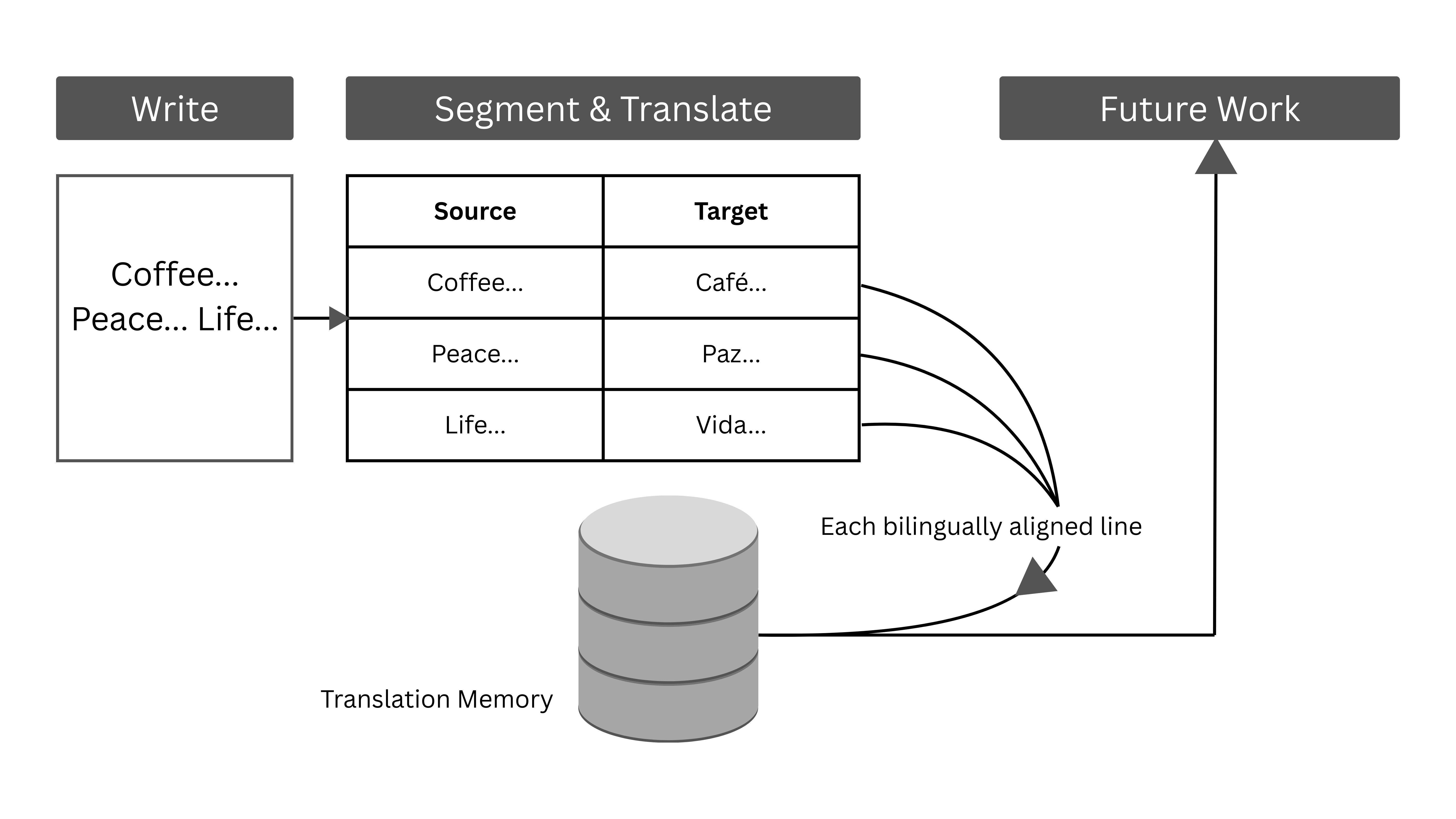
Model 1. The Jail Cell Approach to Translation. This diagram shows how we take content that was written naturally and divide it up into individual sentence cells. Each sentence is locked into its cell, paired with its translation and then stored away in a translation memory database to be recycled into future projects.
Moreover, at SlatorCon Silicon Valley 2024, “hyper-personalization” was the buzzword dominating the conference sessions. Since generative AI became widely popularized, we’ve been hearing plenty about how it’s disrupting our industry too.
But is incorporating generative AI into existing translation technology actually disruptive? I don’t think so. And that same sentence-by-sentence approach? It’s not going to deliver the hyper-personalization that people were talking about at the conference either.
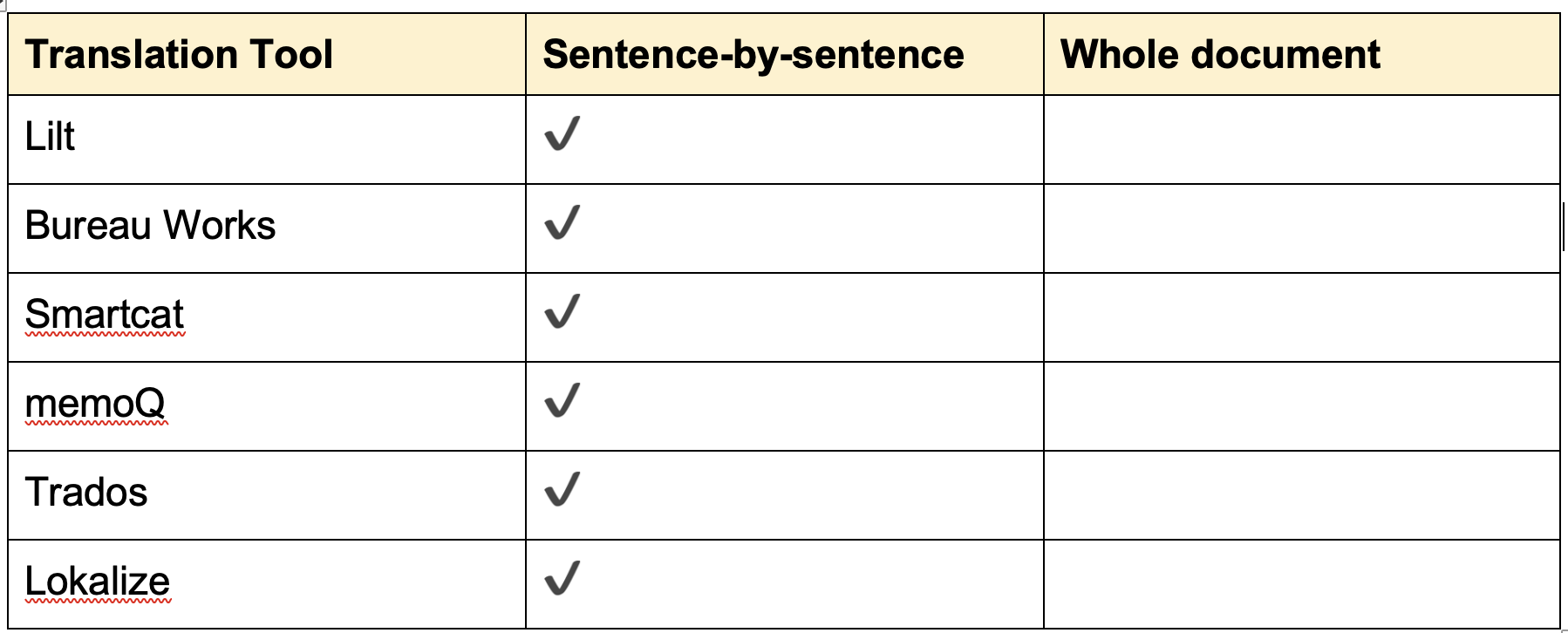
Table 1. Popular translation tools and their approach to content
Sentence-by-sentence translation prohibits pragmatic restructuring
But why doesn’t the current approach work for hyper-personalization? Because sentence-by-sentence translation prevents the kind of pragmatic restructuring that makes content flow naturally for different audiences. For non-linguistic folks out there, pragmatics is a level of textual meaning that deals with how well content flows as a whole textual unit and, beyond that, how well content fits within the larger cultural context to which it corresponds.
There’s no shortage of examples of how current technology prevents the necessary pragmatic restructuring of translations. Take paragraph structure, for instance. English writing typically starts with a topic sentence, then expands on that idea throughout the rest of the paragraph. Mandarin paragraphs often work the opposite way. They build toward the topic sentence, which serves as the paragraph’s conclusion.
Mona Baker addresses this issue in her chapter “Pragmatic Equivalence” from In Other Words. She explains the theory behind why sentence-by-sentence translations fail to create pragmatically appropriate texts, giving many practical examples. My knowledge of both theory and practice is why I call the method that traditional computer-assisted translation tools keep us trapped in the “jail cell” approach. In translation technology, the source content’s structure is forced onto the target text through rigid sentence ordering.
That said, truly disruptive technology designed to help writers to achieve hyper-personalization would leverage generative AI’s extended context window differently. Instead of processing texts sentence by sentence, technology would allow us to work with entire texts and enable the pragmatic restructuring that makes content feel truly personalized. In fact, recent studies highlighted by Slator show promising research happening in Europe and China on exactly this kind of document-level approach.
This document-level shift moves us away from treating source texts as “originals” and translations as mere derivatives. Instead, it gives all languages equal priority.
Developers and companies and their jail cell approach
So why don’t more developers and companies recognize the issue with the current translation memory approach? Well, the status quo exists for a reason. For years, companies have been selling the “recycling center” method to clients, promising cost savings and faster turnaround times. The pitch is simple. Store every sentence with its translation in a bilingual database, then “leverage” that content for anything new you write.
Nevermind that I challenge you to find a single author who stores their writing sentence-by-sentence so they can recycle exact formulations into their future work. No writer works that way. But clients bought into the value proposition of the translation memory, and after years of building up these databases, most won't be willing to let this approach go.
Michael Reid often points out another crucial factor. Most big translation companies aren’t run by writers or translators. They’re run by business people and developers—many of them monolingual—who prioritize business goals and development roadmaps that disregard what translation actually requires. The business and development mindset often ignores the key moral principle that everyone deserves content and systems thoughtfully designed for their context. The way to create thoughtfully designed products is by putting in-culture experts in decision-making roles.
If more technology developers came from writing and translation backgrounds, or listened to writers and translators, they might build more features that reflect how writing and localization actually work. That includes the document-level segmentation I’m advocating for here. Another example of a beneficial feature: being able to edit and download updated source texts after translation, since translation often reveals ways to improve the original content. You only recognize the value of features like this when you’ve actually done the work of writing and translating.
What does this have to do with hyper-personalization?
The status quo of translation treats all audiences the same, using sentence-by-sentence translation without considering how content needs might vary across groups of readers. The term hyper-personalization in and of itself conveys the need to move away from that approach.
So let’s explore the concept of hyper-personalization in translation. We can start by considering the audience of communications. Your U.S. audience might be baby boomers, millennials or generation alpha. In Mexico, the audience may be fresas or nacos. Each group requires different language to connect with them effectively. Hyper-personalization in translation means identifying your specific audience group, then writing directly to them, and sometimes even creating multiple versions of the same content for different groups.
Yet, a strategy of hyper-personalization goes beyond only defining the audience. More characteristics of communication must be considered as well. For instance, is the author of the content meant to come off as a subject matter expert? An academic? A copywriter? What point of view will the author be taking? What’s the purpose of the content? Is it meant to be persuasive or informational? How widely will the content be disseminated?
These questions point to gaps in current practice: hyper-personalization requires that the audience of a translation has been defined well beyond the typical use of language variants in the language services industry. To illustrate, Spanish for Mexico is a language variant, NOT a way of defining the audience of a translation.
The solution: Take a pragmatic approach to translation
If you’ve realized that sentence-by-sentence translation isn’t the way to achieve true hyper-personalization, I’d encourage you to start thinking about a pragmatic shift: carefully define your audience, then make space for creative restructuring so content can be written specifically for that audience in translation. This requires taking a whole-document rather than a sentence-by-sentence approach.
Such an approach means elevating the work of in-culture experts like translators too. But translators face the same challenge we all do as an industry. We’ve all become accustomed to treating translation as mechanical sentence-by-sentence reproductions rather than valuing it as the meaningful communication through which we can connect with people. Moving toward hyper-personalization will require significant collective unlearning.
And now that I’ve finished writing the body of this article, let me go back through it and add a few headers, do some rearranging and another couple rounds of editing. You know, the kind of holistic restructuring that translation memories prevent, which is exactly what writing actually looks like.
Expand Your Localization Expertise. Subscribe to Our Newsletter!

Alaina Brandt
Alaina Brandt is a professor of translation and localization at Universidad Intercontinental in Mexico City. She holds a Master of Arts in Language, Literature and Translation, specializing in Spanish to English translation, along with professional development certificates in generative AI and machine learning/data science from MIT. Brandt serves as Membership Secretary of ASTM F43 on Language Services and Products, a technical committee that produces international standards for translation and localization. She previously served on the Board of Directors of the American Translators Association from 2019 to 2023. Her experience includes translation and localization management in more than 80 languages, with teaching experience ranging from elementary education to graduate and professional development programs. Connect with Alaina on LinkedIn (https://www.linkedin.com/in/alainambrandt/) and via GitHub (https://github.com/alainamb).